AI LLM lokal betreiben - GPUs verknüpfen mit exo AI Cluster

LLM lokal betreiben für höchste Datensicherheit. Das ist wofür wir stehen. In diesem Tutorial zeigen wir dir, wie du mit Exo ganz einfach den Grafik-Speicher aller deiner Heimgeräte (PC, Mac, Raspberry Pi) kombinieren kannst, um so auch leistungsstärkere Open Source KI LLM lokal zu hosten.
KI Large Language Model lokal betreiben - GPUs verknüpfen mit exo AI Cluster
Hallo Zusammen, unser letztes Tutorial ist schon eine Weile her, da wir unsere Webseite neu aufgebaut haben. Aber jetzt ist es Zeit für ein neues Thema, was aktueller nicht sein kann.
In diesem Tutorial zeigen wir dir, wie du mit wenigen Klicks mehrere Computer (Macs Linux Raspberry Pi) miteinander zu einem Cluster verbindest, um dein eigenes LLM AI Model lokal zu betreiben. Damit du garantiert sicher vor den Augen dieser Zucks, Altmans, Musks und Xis dieser Welt bist. Legen wir los.
Wichtiger Hinweis:
Zum aktuellen Stand (25.08.2025) wird der Raspberry Pi von Exo offensichtlich nicht unterstützt. Kommentare auf GitHub lassen ähnliches verlauten. Alle Versuche, die ich unternommen habe, haben zwar alle Fehler beseitigt, jedoch erscheint keine Ausgabe, wenn ich einen Prompt eingebe.
Klappt es bei euch? - Dann lasst es mich bitte wissen in den Kommentaren. oder per Mail.
Wieso ein AI Model lokal betreiben
In den USA gibt es eine schöne Redewendung die heißt: “You either pay for the product or you are the product”. Soll heißen, entweder du bezahlst ein Produkt mit Cash oder du bezahlst halt mit deinen Daten. ChatGPT, Gemini, Mistral, Claude sind alles wahnsinnig hilfreiche LLM KI Chatbots. Aber wenn wir zukünftig planen, dass eine KI unsere Termine plant, E-Mails beantwortet, Essen auf Basis unserer Vorlieben bestellt oder den nächsten Urlaub plant, wollen wir dann zulassen, das OpenAI und Google Zugriff auf alle unsere Daten bekommen? Ich nicht. Aber es geht nicht nur um wollen - in manchen Aspekten hindert uns sogar das Gesetz. Stichwort DSGVO. Insbesondere, wenn wir unsere E-Mails und Chatnachrichten verarbeiten möchten.
Es gibt etliche Open Source (bzw. Open Weight) LLMs, die frei zum Download zur Verfügung stehen. Zum Beispiel hatte Meta sein Model namens “LLaMA” öffentlich zur Verfügung gestellt, als es gemerkt hat, dass es im Rennen um AI ins Hintertreffen geraten war. Auf dessen Basis sind nun mehrere Forks und freie Community Versionen entstanden. Darunter zum Beispiel auch Mistral. Auch OpenAI hat kürzlich ihr o4-mini Modell frei zur Verfügung gestellt (gpt-oss). Ich finde das einen tollen Schritt - wenn auch tendenziell zu groß für den Heim-PC (oder den geplanten Heim-Cluster).
Eines dieser kostenfreien Models werden wir nutzen um, es bei uns lokal betreiben. Somit verlassen dann auch die Daten nicht dein Haus, sodass du auch problemlos schützenswerte Inhalte oder personenbezogene Daten verarbeiten kannst, ohne dir Sorgen zu machen.
Large Language Models + Grafikspeicher (GPU) = ❤️
KI Models sind bekannt dafür, sehr rechenintensiv zu sein. Insbesondere GPUs, also Grafikspeicher liebt ein Large Language Model am liebsten, da sie für die Verarbeitung einen nicht geringen Betrag an Video-RAM (vRAM) benötigt. Das ist das, was NVIDIA gerade so unglaublich glücklich macht. Denn die meisten der KI-Models, wurden auf NVIDIA Grafikkarten trainiert und funktionieren deshalb auch am besten auf diesen. Das heißt aber nicht zwangsläufig, dass es ein NVIDIA Chip sein muss.

Jen-Hsun Huang - Nvidia CEO treffend illustiert.
Die benötigte Rechenleistung und die Größe des KI Modells bemisst sich unter anderem daran, auf wie vielen Parametern es trainiert wurde (gibt aber nicht zwingend gleichzeitig Aussage über die Qualität). Ich will nicht zu tief in die Materie einsteigen, deshalb eine vereinfachte Erklärung:
Jedem KI-Model liegt ein neuronales Netz zu Grunde. Je komplexer ein Netz, desto höher die Anzahl der Parameter (Menge der Neuronen respektive Wichtungen und Biases) und desto höher die Fähigkeit des LLMs komplexe Zusammenhänge zu verstehen.
Und die Menge der Daten, auf der es trainiert wurde, gibt Aussage über das verfügbare “Wissen” des Models.
Grundregel:
• Anzahl Parameter = Modellgröße & Kapazität
• Datenmenge = Qualität & Vielfalt des Gelernten
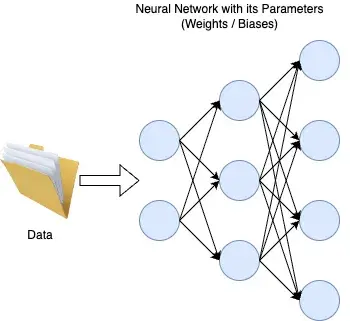
Grundprinzip
Wir nutzen in diesem Tutorial ein (zum Zeitpunkt des Erscheinens) relativ junges Tool namens Exo. Das Prinzip ist ganz einfach, wenn auch genial.
Wie wir kennengelernt haben, brauchen wir viel Video-RAM, um ein Model bei uns gut betreiben zu können. Und Exo hat sich da etwas cleveres ausgedacht: Dieses Tool verbindet einfach mehrere Computer (genannt Nodes) in einem Heimnetzwerk miteinander, um die einzelnen vRAM zu kombinieren und somit mehr Rechenleistung zur Verfügung zu stellen. Das einzige was man tun muss, ist Exo auf jeder einzelnen Maschine zu starten.
Voraussetzungen
Hardware
Als erstes lasst uns erst einmal darüber sprechen, was wir brauchen.
Im Grunde kann es jeder Heim-PC sein. Sei es ein Mac oder ein Windows PC oder eben ein Raspberry Pi (noch nicht supported). Hast du zum Beispiel einen ziemlich aktuellen Gaming PC, der mit einer neueren NVIDIA Grafikkarte läuft und über einen großzügigen Grafikspeicher verfügt, hast du gute Karten. Aber auch, wenn du einen Mac mit Silicon Chip (also die M1, 2, 3, 4 usw. Serie) oder einen Raspberry Pi mit reichlich RAM hast, hast du gute Möglichkeiten, ein LLM zu betreiben. Denn sowohl die Silicon Chips als auch die Pi basieren auf der ARM Prozessorarchitektur. Diese nutzen unified Memory. Heißt, dass der RAM Speicher zwischen Memory und Grafik aufgeteilt wird. Bedeutet, wenn du 8 GB RAM hast, aber gerade kaum Arbeitsspeicher-intensive Prozesse laufen hast, kann der gesamte Speicher für Grafikressourcen aufgebraucht werden, was praktisch für den Betrieb unsere lokalen KI ist.
Lange Rede, kurzer Sinn: Bei Geräten mit aktuellen Grafikkarten von NVIDIA oder Geräten, welche auf der ARM Architektur laufen und etwas an RAM mitbringen (RPi, Apple mit Silicon Chip), hast du gute Chancen
Und Exo schaltet nun alle mehrere Geräte zusammen um deren Grafikspeicher zu kombinieren. Das ganze nennen wir dann Cluster. Cool oder?
Softwarelandschaft
Disclaimer: Das Tutorial basiert auf dem Mac und Raspberry Pi. Wir nutzen also shell. Ggf. gibt es eine abweichende Syntax bei Windows.
Exo läuft auf der Programmiersprache Python.
Auf ihrer offiziellen GitHub Seite empfehlen sie die Nutzung der Version 3.12 - die würde ich euch auch raten zu nutzen. Ich selbst hatte es mit der 3.13 versucht und es hat nicht geklappt.
Die installation anderer Python Versionen kann manchmal ein bisschen tricky sein, deshalb empfehle ich euch die Nutzung von Pyenv. Damit könnt ihr auf einfachem Weg mehrere Python Versionen auf eurem Gerät nutzen.
Hier die Schritte, wie ihr die richtigen Bedingungen schaffen könnt:
1. Python Version prüfen
python3 -- version
Hast du eine 3.12 Version, dann bist du fein, wenn nicht folge den Schritten zum Installieren einer neuen Python Version via Pyenv.
1.1 Nicht Version 3.12? Pyenv installieren
Mac:
Mit Homebrew (kein homebrew? -> Installationanleitung hier):
brew update
brew install pyenv
pyenv install 3.12
Raspberry Pi (OS):
A. Installieren
curl -fsSL https://pyenv.run | bash
B. Home Path setzen
- Für .bashrc
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo '[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init - bash)"' >> ~/.bashrc
- Und für .profile
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.profile
echo '[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.profile
echo 'eval "$(pyenv init - bash)"' >> ~/.profile
C. Shell neu starten
exec "$SHELL"
D. Python Dependencies installieren (einfach im Ganzen copy und pasten)
sudo apt update; sudo apt install make build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev curl git \
libncursesw5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev liblzma-dev
E. Pyenv installieren
Nach den vielen extra Schritten, kannst du jetzt auch die passende Python Version auf dem Pi installieren:
pyenv install 3.12
Die Aktivierung von lokalen Python Version mit pyenv ist weiter unten in der Intstallationsbeschreibung beschrieben.
Bist du auf einem anderem System unterwegs, dann schau im pyenv Repository nach der passenden Installationsanleitung für dein Betriebssystem.
Installation
Das ganze Vorgeplänkel ist tatsächlich der längste Part, denn die Installation ist total simpel. Abgesehen von einigen extra Schritten, die wir wieder auf dem Raspberry Pi durchführen müssen.
Hier sind die Schritte, die auf den Nodes (also auf den Geräten) durchgeführt werden müssen, um exo zu installieren. Öffne hierzu das Terminal:
2. Exo herunterladen
git clone https://github.com/exo-explore/exo.git #exo herunterladen (in das Verzeichnis in dem du dich gerade befindest)
cd exo #in das verzeichnis wechseln
2.1 Optional: Aktiviere eine lokale Python 3.12 Version mit pyenv
pyenv benötigen nur jene, die nicht Python 3.12 nutzen. Für diese Schritte schaut unter "Voraussetzungen" (Schritt 1) nach.
pyenv local 3.12 #aktiviere die zuvor installierte pyenv Version in dem Ordner
3. Virutelle Python Umgebung erstellen
python3.12 -m venv venv #erstelle eine virtuelle Umgebung, um deinen Computer sauber zu halten
source venv/bin/activate #aktivieren die erstellte virtuelle Umgebung
Kleiner Hinweis zur Arbeit mit einer VENV (Virtuellen Umgebung): Wenn ihr das Terminal öffnet, ist automatisch euer "home"-Pfad ausgewählt. Für den Mac ist das Heim-Verzeichnis zum beispiel Users/BENUTZERNAME. Sofern ihr diesen Pfad nicht ändert, wird exo dort heruntergeladen. Eine Virtuelle Umgebung ist ein abgeschotteter Bereich, auf dem die jeweiligen Tools & Libraries installieren könnt. Diese existieren dann nur innerhalb dieser Umgebung. Das sorgt dafür, dass du diese einfach löschen kannst, wenn du sie nicht mehr brauchst und dass es nicht zu eventuellen Konflikten mit anderen Tools auf deinem PC kommt. Die VENV haben wir in dem Ordner Exo erstellt. Wenn du das Terminal schließt, musst du erst wieder in das entsprechende Verzeichnis wechseln cd exo und diese Virtuelle Umgebung wieder aktivieren source venv/bin/activate. Das ist wichtig - sonst klappts nicht!
3.1 Notwendige Zwischenschritte mit Raspberry Pi
Für eine saubere Installation auf dem Raspberry Pi, müssen wir einige Softwarepakete aufräumen und installieren. Hierfür führe folgende Schritte durch:
Pip cache purge
Pip install regex # deprecation Warnung für wheels beseitigen
sudo apt update
sudo apt install -y libdrm-dev pkg-config build-essential python3-dev # installiere notwendige Abhängigkeiten
pip install --no-cache-dir pyamdgpuinfo #installiert AMD GPU Support - was sinnlos ist, da wir ja keine haben - aber im exo Installationsprozess brauch er es - um es dann auch direkt während der installation wieder zu deinstallieren
Wichtiger Hinweis:
Zum aktuellen Stand (25.08.2025) wird der Raspberry Pi von Exo offensichtlich nicht unterstützt. Kommentare auf GitHub lassen ähnliches verlauten. Alle Versuche, die ich unternommen habe, haben zwar alle Fehler beseitigt, jedoch erscheint keine Ausgabe, wenn ich einen Prompt eingebe.
Klappt es bei euch? - Dann lasst es mich bitte wissen in den Kommentaren. oder per Mail.
3.2 Notwendige Zwischenschritt für Mac
Aktueller Bug Mac Silicon zum 20.08.25: Es wird im Exo Installations Skript eine MLX Version gesucht, die nicht mehr existiert. Um das zu fixen, öffne mit einem Code Editor das file “setup.py” im Exo Ordner, suche nach “mlx” und ändere die Version von 0.22.0 auf 0.22.1.
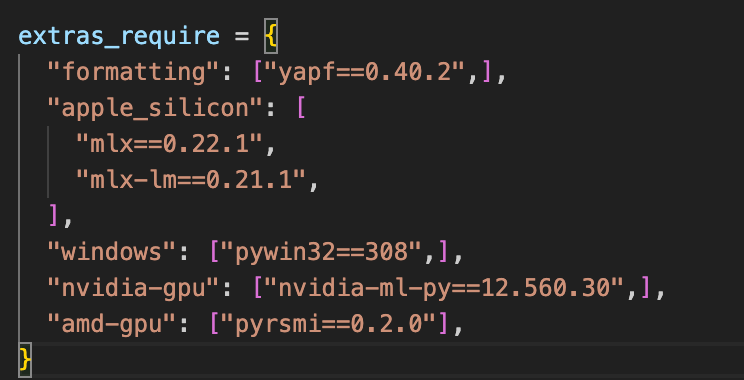
Es ist möglich, dass der Bug in Zukunft verschwunden ist. Wenn euch auffällt, dass da schon eine neuere MLX Versionen drinnen steht, dann lasst es so wie es ist.
4. Exo installieren
Nach allen Vorbereitungen und Zwischenschritten, solltet ihr Exo final installieren können. Hierfür solltet euch mit dem Terminal im Exo Verzeichnis befinden.
pip install -e
5. Exo starten
exo
Starte nun Exo auf allen deinen Geräten - That's it! Mit dem Befehl sucht es automatisch alle Nodes im Netzwerk, die Exo gestartet haben und schaltet sie zusammen. Der Balken ist ein Indikator für die gemeinsame Grafikspeicher GPU Performance.
Im Terminal sieht das dann so aus:

Hier gerade nur mit einer aktiven Node. Wenn du mehrere in deinem Netzwerk zuschaltest, dann erscheinen diese in einem Grid darunter und die TFLOPs summieren sich in dem Balken
Du kannst jetzt das Chat-Interface öffnen unter folgender URL:
- http://192.168.64.1:52415
Tipp:
Wenn du es in anderen Tools (wie zum Beispiel dem Workflow Tool n8n) verwenden möchtest, kannst du auch den API-Endpoint nutzen:
- http://192.168.64.1:52415/v1/chat/completions
Das Request-Format sollte sich an dem der ChatGPT API orientieren (Doku siehe hier). Inwiefern diese aktuell gehalten wird, kann ich jedoch nicht sagen.
Links vom Chat Fenster siehst du eine Auswahl aller LLM Models. Nun kommt das, was ich Eingangs erwähnt habe. Du hast zwei Indikatoren dafür, wie mächtig das Model ist. Die Anzahl der Parameter im Neuronalen Netz, auf dem das Large Language Model trainiert wurde: Diese findest du oft (nicht immer) rechts neben dem Model: "Llama 3.3 70B" bedeutet, dass das Model auf 70 Millarden (in englisch Billion) Parametern trainiert wurde. Darunter siehst du die Größe des Models. Die Größe hängt unmittelbar mit der Menge der Parameter zusammen.
Die Auswahl des richtigen Models beruht demzufolge auf folgenden Faktoren:
- Wie komplex ist die Aufgabe, die das Large Language Model lösen soll?
- Wie viel GPU habe ich?
- Wie viel Speicherplatz habe ich?
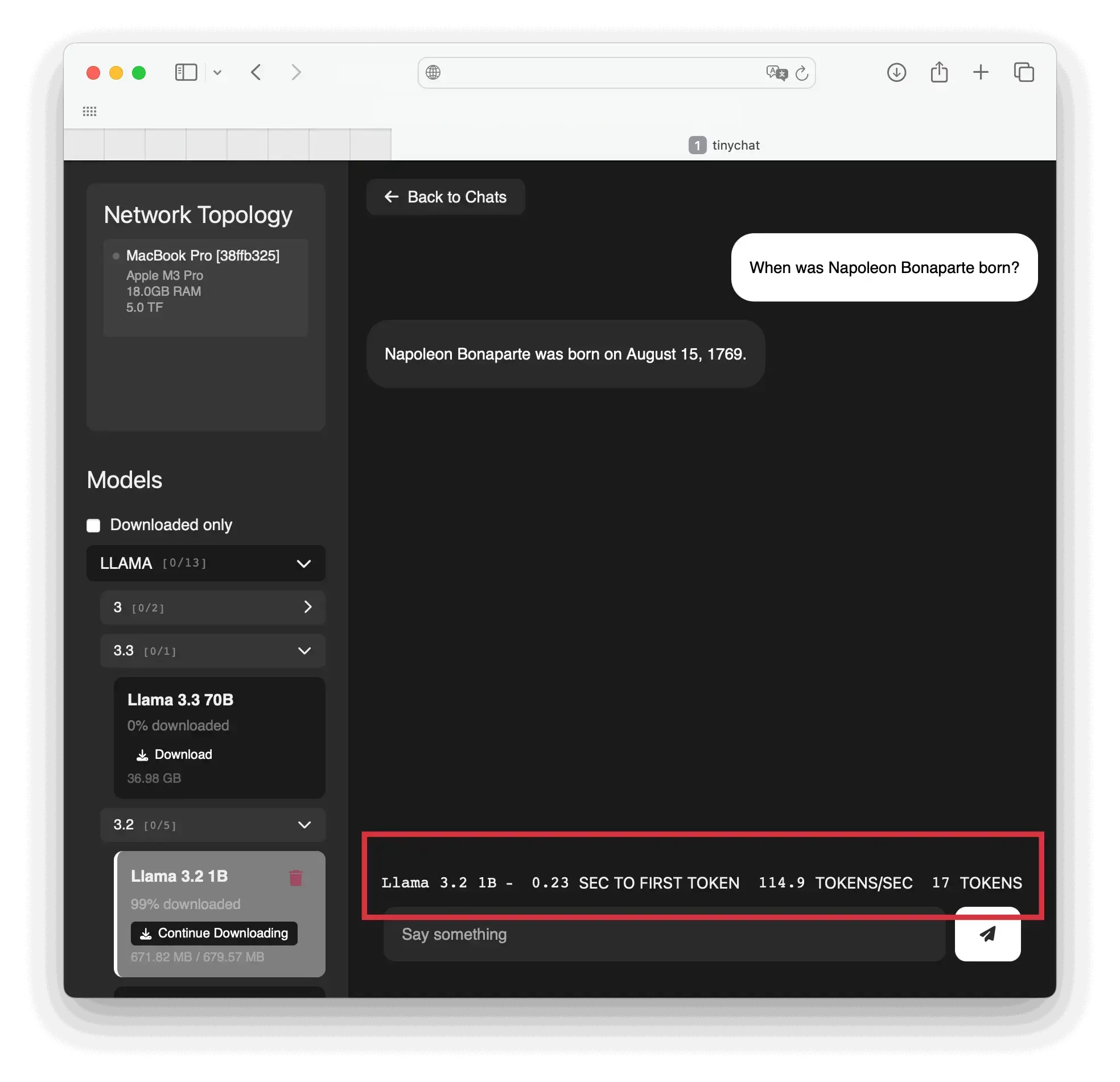
Lade dir zum Test erst einmal ein kleines Model herunter. Zum Beispiel "Llama 3.2 1B" mit verkraftbaren 680 Megabyte. Wähle es aus und gib deinen Befehl in der Chat Zeile ein. Auf jeder Node wird das Model jetzt vorerst heruntergeladen. Unten hast du nun zwei Indikatoren für die Performance. Zum einen die Token pro Sekunde (höher ist besser) und die Sekunden bis zum ersten Token (geringer ist nur bedingt besser - bei "Reasoning" Models, also die die erstmal "Nachdenken" bevor sie was ausspucken, kann der erste Token etwas länger dauern).
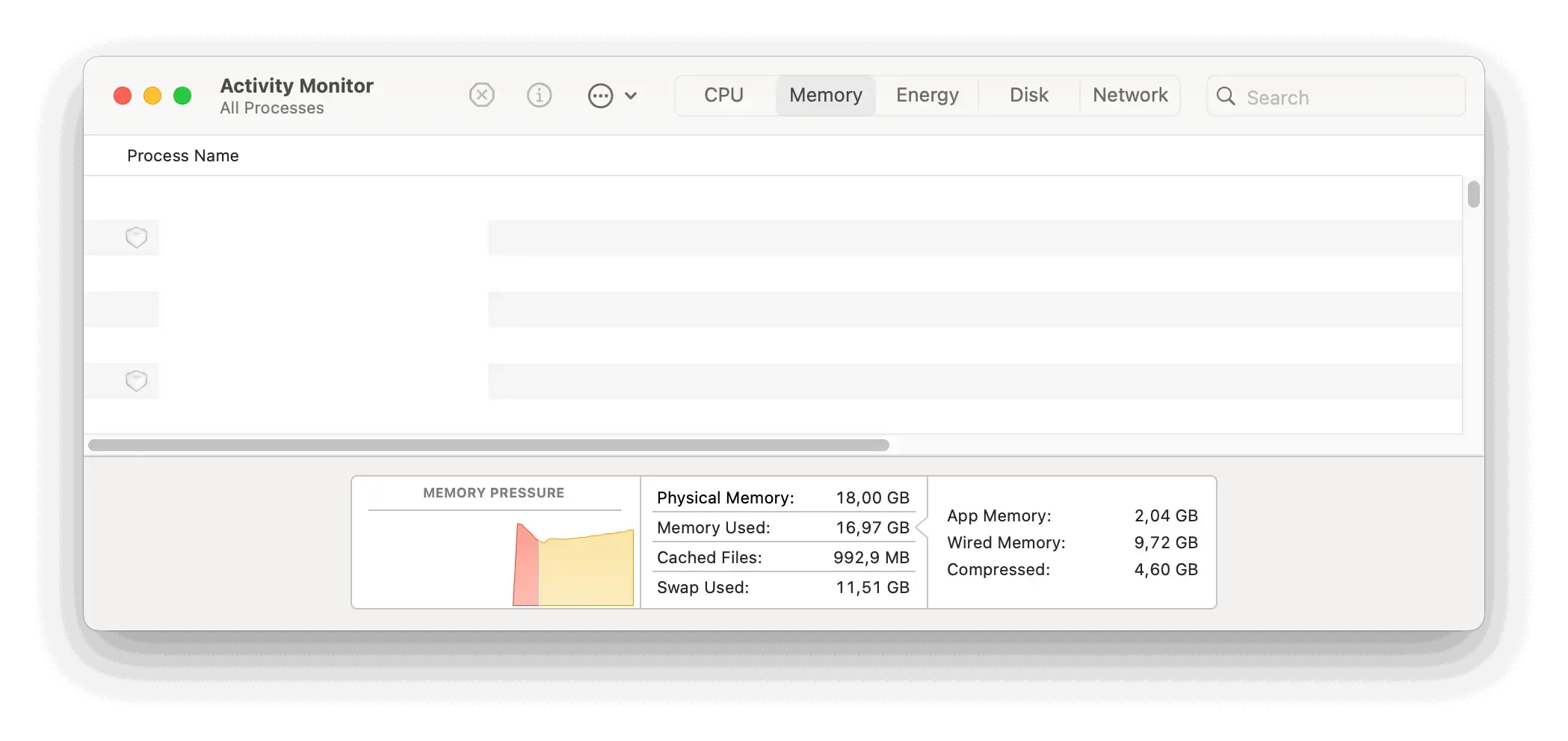
Im Activity Monitor kannst du auch sehen, wie sehr deine Rechner mit dem Model zu kauen haben.
Taste dich heran und schau, welches Model dir am besten passt. Bedenke nur, dass die meisten kleinen Models oft nur auf Englisch trainiert wurden. Die Deutsche Ausgabe kann manchmal inkorrekt sein (Grammatikalisch wie Faktisch).
Weiterhin kannst du jetzt auch die Performance mit mehr und weniger Nodes testen.
Tipp:
GPUs über das Netzwerk zusammenzuschalten ist die eine Sache. Aber man sollte immer seine Bottlenacks im Blick behalten - und das ist in diesem Fall das Netzwerk. Vergleiche WLAN mit LAN Verbindung in dem du mit jeweils den gleichen Models, die gleichen Prompts eingibst und dann die Token pro Sekunde vergleichst (wähle möglichst ein Prompt der nicht viel Interpretationsspielraum für die KI lässt, damit sich die Ausgabe pro Prompt nicht zu sehr unterscheidet, um möglichst gleiche Testbedingungen herzustellen).
Fazit
Exo hat wirklich potenzial, für Privatpersonen oder Firmen, die KI Large Language Models lokal betreiben möchten (Geeks wie mich ...). Ich finde es sprechen viele Argumente dafür: Datensicherheit, eigene Auswahl des Models (man denke nur an Elon Musk - der Grok nach seinen Weltanschauungen formt) und die Einbindung in Workflows, wo du die KI für Automatisierungen oder als digitalen Assistenten nutzen kannst. Doch muss sich Exo noch weiterentwickeln, um weniger fehleranfällig zu sein und mehr Geräte unterstützen. Sicherlich braucht es auch noch ein nutzerfreundliches Interface, wenn es irgendwann für den breiteren Einsatz genutzt werden soll. Ich hoffe sie machen weiter. Ich freue mich auf Updates und werde den Blogbeitrag zu gegebener Zeit den neuen Gegebenheiten anpassen.
In dem Sinne - Viel Spaß beim Testen - Cheers






Bemerkungen
Zur Zeit kein Kommentar!
Hinterlasse ein Kommentar