Nach dieser Lektion weißt du wie der PIR Sensor HC-SR501 von Electreeks aufgebaut ist, wie er funktioniert und wie du...
Latest posts
-
 Anschließen des PIR Sensors HC-SR-501 und Exkurs in die FunktionsweiseMehr lesen
Anschließen des PIR Sensors HC-SR-501 und Exkurs in die FunktionsweiseMehr lesen -
 Fernzugriff auf MotionEye-OS und Raspberry Pi durch Portfreigabe und DynDNSMehr lesen
Fernzugriff auf MotionEye-OS und Raspberry Pi durch Portfreigabe und DynDNSMehr lesenAus dem Internet auf Motion Eye zugreifen. Ports freigeben im Router und per DynDNS dauerhaft aus dem Internet...
-
 E-Mail versenden nach Bewegungserkennung in MotionEye-OSMehr lesen
E-Mail versenden nach Bewegungserkennung in MotionEye-OSMehr lesenIn diesem kurzen Videotutorial erfährst du, wie du ganz schnell deine E-Mail (hier Gmail) in Motion-Eye-OS...
-
 Bilderkennung mit Electreeks® SpyAgentMehr lesen
Bilderkennung mit Electreeks® SpyAgentMehr lesenEin einfaches Objekterkennungstool Gemacht mit ❤️ von uns! Setz eine AI Bilderkennung auf deinen Raspberry Pi...
-
 Internet Live-Stream mit einer Raspberry Pi Kamera auf YouTube mit Motion-Eye-OSMehr lesen
Internet Live-Stream mit einer Raspberry Pi Kamera auf YouTube mit Motion-Eye-OSMehr lesenErstell jetzt mit deiner Raspberry Pi Kamera einen Livestream auf YouTube mit MotionEyeOS und teil ihn mit anderen...
-
 MotionEye-OS Tutorial – Alle Funktionen von Motion Eye erklärtMehr lesen
MotionEye-OS Tutorial – Alle Funktionen von Motion Eye erklärtMehr lesenManche Features von MotionEye sind nicht unbedingt selbsterklärend: Deshalb beschreiben wir dir in diesem Tutorial...
-
 Bilderkennung mit OpenCV und MobileNet auf dem Raspberry PiMehr lesen
Bilderkennung mit OpenCV und MobileNet auf dem Raspberry PiMehr lesenMit Electreeks in die Welt der künstlichen Intelligenz (KI) einsteigen. Heute bekommst du einen kleinen Exkurs in die...
-
 Nistkasten Kamera Bauanleitung – Kamera für Vogelhaus mit Raspberry Pi selber bauenMehr lesen
Nistkasten Kamera Bauanleitung – Kamera für Vogelhaus mit Raspberry Pi selber bauenMehr lesenIn diesem Tutorial zeigen wir dir, wie du mit einem Raspberry Pi und einer Electreeks Raspberry Pi Kamera eine eigene...
-
 Raspberry Pi Kamera im LXTerminal ansteuernMehr lesen
Raspberry Pi Kamera im LXTerminal ansteuernMehr lesenIn diesem Tutorial findest du in einem kompakten Überblick alle erdenklichen Befehle, um deine Raspberry Pi Kamera...
-
 Python GPIO Befehle im Überblick – Raspberry PiMehr lesen
Python GPIO Befehle im Überblick – Raspberry PiMehr lesenDie GPIO zählen bis zu 40 steuerbare Pins auf dem Raspberry Pi. Diese GPIO kann man individuell als Eingang und...
Blog categories
Search in blog
Archived posts

Bilderkennung mit OpenCV und MobileNet auf dem Raspberry Pi
Mit Electreeks in die Welt der künstlichen Intelligenz (KI) einsteigen. Heute bekommst du einen kleinen Exkurs in die Bilderkennung und Objekterkennung mit OpenCV und MobileNet auf dem Raspberry Pi.
|
Downloads zu diesem Tutorial: |
 |
Vorbereitung
|
Um starten zu können, benötigst du folgende Dinge:
Die Micro-SD Karte sollte mit einem aktuellen Raspbian OS bespielt sein (Stretch oder Buster – Programmiert wurde mit Stretch). Du hast noch kein Betriebssystem installiert? Mit dem Raspberry Pi Imager von der Raspberry Pi Foundation geht es am schnellsten. |
 |
Nachdem du die Komponenten angeschlossen hast und das Betriebssystem bereit ist, empfiehlt sich im nächsten Schritt ein Update mit anschließendem Neustart. So stellen wir sicher, dass alles auf dem neuesten Stand ist. Dafür wird eine Internetverbindung vorausgesetzt. Öffne das LXTerminal und gib folgenden Befehl ein:
sudo apt-get updateProzedur
Erstelle als erstes unter Verwendung der Dateiendung “.py” eine Python-Datei und speichere diese in deinem Home-Verzeichnis ab. In unserem Verzeichnis ist das die “main.py”. Zur Umsetzung der Bilderkennung nutzen wir diverse OpenSource-Anwendungen.
MobileNet
MobileNet ist ein Objekterkennungsmodell speziell für Geräte mit geringerer Rechenleistung. Die Erkennung verläuft über eine mathematische Methode namens Konvolution (Convolution), oder auch Faltung genannt. Dadurch wird eine feinkörnige Analyse des Bildes auf mehreren Ebenen gewährleistet, wodurch einzelne Merkmale auf dem Bild ausgewertet werden können. Entscheidend ist am Ende die Wahrscheinlichkeit der Existenz eines Objekts innerhalb der vortrainierten Klassen, welche unten aufgeführt werden.
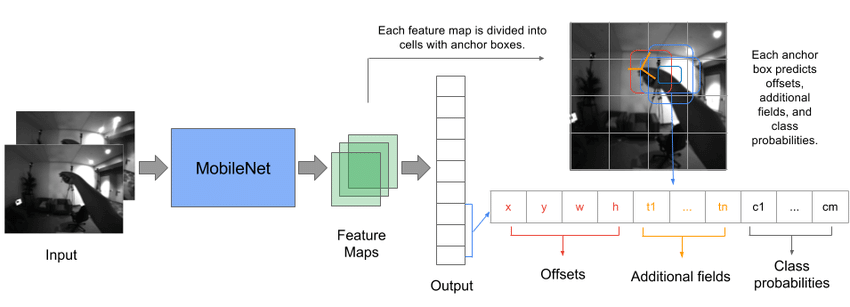
Bildquelle: Link zur Abbildung [21.01.2020]
{kind=link}
OpenCV
OpenCV nutzen wir für die prozessuale Abwicklung der Bilderkennung. Wir laden damit die Klassen (Bibliothek der zu erkennenden Objekte), verarbeiten das betreffende Bild und geben die erkannten Objekte (Klassennummer) mit den jeweiligen Positionen als eingezeichnetes Rechteck zurück.
Zur Nutzung ist ein Modul namens OpenCV notwendig. Mit folgendem Befehl in der Konsole (LXTerminal) kannst du es installieren:
pip install opencv-pythonSollte es auf diesem Weg nicht funktionieren, versuch folgenden längeren Befehl:
sudo apt install libatlas3-base libwebp6 libtiff5 libjasper1 libilmbase12 libopenexr22 libilmbase12 libgstreamer1.0-0 libavcodec57 libavformat57 libavutil55 libswscale4 libqtgui4 libqt4-test libqtcore4
sudo pip3 install opencv-python
Coding
Kommen wir nun zur eigentlichen Programmierung mit Python und dem Raspberry Pi.
1. Klassen definieren
Das Modell ist für 90 Klassen von Objekten wie Couch, Toaster, Mikrowelle, Pizza und Elefant etc. ausgebildet und getestet. ObjectsNames ist ein Dictionary, das aus einem Namen von 90 Klassen mit einer ID besteht.
# Pretrained classes in the model
ObjectsNames = {0: 'background',
1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorcycle', 5: 'airplane', 6: 'bus',
7: 'train', 8: 'truck', 9: 'boat', 10: 'traffic light', 11: 'fire hydrant',
13: 'stop sign', 14: 'parking meter', 15: 'bench', 16: 'bird', 17: 'cat',
18: 'dog', 19: 'horse', 20: 'sheep', 21: 'cow', 22: 'elephant', 23: 'bear',
24: 'zebra', 25: 'giraffe', 27: 'backpack', 28: 'umbrella', 31: 'handbag',
32: 'tie', 33: 'suitcase', 34: 'frisbee', 35: 'skis', 36: 'snowboard',
37: 'sports ball', 38: 'kite', 39: 'baseball bat', 40: 'baseball glove',
41: 'skateboard', 42: 'surfboard', 43: 'tennis racket', 44: 'bottle',
46: 'wine glass', 47: 'cup', 48: 'fork', 49: 'knife', 50: 'spoon',
51: 'bowl', 52: 'banana', 53: 'apple', 54: 'sandwich', 55: 'orange',
56: 'broccoli', 57: 'carrot', 58: 'hot dog', 59: 'pizza', 60: 'donut',
61: 'cake', 62: 'chair', 63: 'couch', 64: 'potted plant', 65: 'bed',
67: 'dining table', 70: 'toilet', 72: 'tv', 73: 'laptop', 74: 'mouse',
75: 'remote', 76: 'keyboard', 77: 'cell phone', 78: 'microwave', 79: 'oven',
80: 'toaster', 81: 'sink', 82: 'refrigerator', 84: 'book', 85: 'clock',
86: 'vase', 87: 'scissors', 88: 'teddy bear', 89: 'hair drier', 90: 'toothbrush'}
2. Vortrainiertes Modell laden
Für die Objekterkennung wird ein vortrainiertes MobileNet-Modell zusammen mit seinen Gewichten verwendet. Es wird mit dem OpenCV DNN-Tool (DNN für deep neural network) mit Tensorflow geladen. OpenCV ist eine Open-Source-Bibliothek für maschinelles Lernen und verfügt über umfangreiche Befehle zur Gesichts-, Objekterkennung uvm. Dazu müssen wir folgende Datei einlesen:
# Loading model
model = cv2.dnn.readNetFromTensorflow('models/frozen_inference_graph.pb',
'models/ssd_mobilenet_v2_coco_2018_03_29.pbtxt')
Diese Dateien, welche im obigen Befehl geladen werden, solltest du vorher auf deinem PC abgespeichert haben. Sofern du die Dateien oben noch nicht gedownloadet hast, hast du hier noch einmal den Downloadlink:
Pretrained Model auf GitHub herunterladen
Stelle sicher, dass sich die Dateien relativ zu deinem Python-Skript, in einem Unterordner namens “models” befinden.
3. Bild einfügen
|
Das vortrainierte Modell kann an Videostreams oder Bildern angewandt werden. In diesem Tutorial nehmen wir Bilder als Input. Das Bild wird mit OpenCV gelesen. Dann werden Bildhöhe und -breite zur weiteren Verarbeitung in Variablen gespeichert. |
 |
4. Verarbeiten des Bildes
Das Bild wird jetzt mit folgendem Kommando bearbeitet, damit es nachfolgend ordnungsgemäß auf das Erkennungsmodell angewandt werden kann:
blob=cv2.dnn.blobFromImage(image, size=(299, 299), swapRB=True)
print("First Blob: {}".format(blob.shape))
Der Befehl erzeugt ein 4-dimensionales Objekt (Blob) aus dem Bild in angepasster Größe und vertauschten Blau- und Rotkanälen (wird für die Verarbeitung in OpenCV benötigt, da dieses mit dem BGR statt dem RGB Schema arbeitet).
5. Klassenname aus ID erzeugen
id_Object_class ist eine Funktion, die die vorhergesagte Klassen-ID und das Wörterbuch von Objekten als Eingabe nimmt und dann mit den Schlüssel-IDs des Wörterbuchs vergleicht. Diese Funktion gibt den Namen der Klasse zurück, die mit der vorhergesagten ID verknüpft ist.
def id_Object_class(class_id, classes):
for key_id, class_name in classes.items():
if class_id == key_id:
#compared class id with model predicted id
return class_name
6. Schwellenwert festlegen
detection[1] stellt die Klassen-ID dar, die vom Modell vorhergesagt wird, während detection[2] die Wahrscheinlichkeit für das Vorliegen der entsprechenden Klasse ist. Der Schwellenwert ist auf 0,35 festgelegt. Das bedeutet, dass für alle IDs, deren Wahrscheinlichkeit größer als der eingestellte Schwellenwert ist, id_Object_class aufgerufen wird, um den entsprechenden Klassennamen zu identifizieren. Je höher der Schwellenwert, desto sicherer handelt es sich um das erkannte Objekt.
7. Zeichnen der Rechtecke
Zur Visualisierung der beschrifteten Klasse im Bild werden für jede Klasse begrenzte Kästchen gezeichnet. Diese Rechtecke erfordern eine definierte Breite und Höhe sowie die x- und y-Koordinaten. Der nächste Schritt ist die Skalierung der Box entsprechend der Bildhöhe und -breite. Zum Zeichnen wird der Befehl cv2.rectangle() verwendet. Es nimmt die x- und y-Werte der Box zusammen mit der Rechteckbreite und -höhe als Argument. Die Dicke des Rechtecks wird auf 1 gesetzt, während (23, 230, 210) seine Farbe als RGB zeigt.
Die Funktion cv2.putText() fügt der Box den Klassennamen hinzu. Der Objektname wird als Eingabe an diese Funktion übergeben. Schriftart und Größe des Textes können ebenfalls angepasst werden.
output = model.forward()
for detection in output[0, 0, :, :]:
confidence = detection[2] # confidence for class occurrence
if confidence > .35: # threshold
class_id = detection[1]
class_name = id_Object_class(class_id, ObjectsNames) # calling id_Object_class function
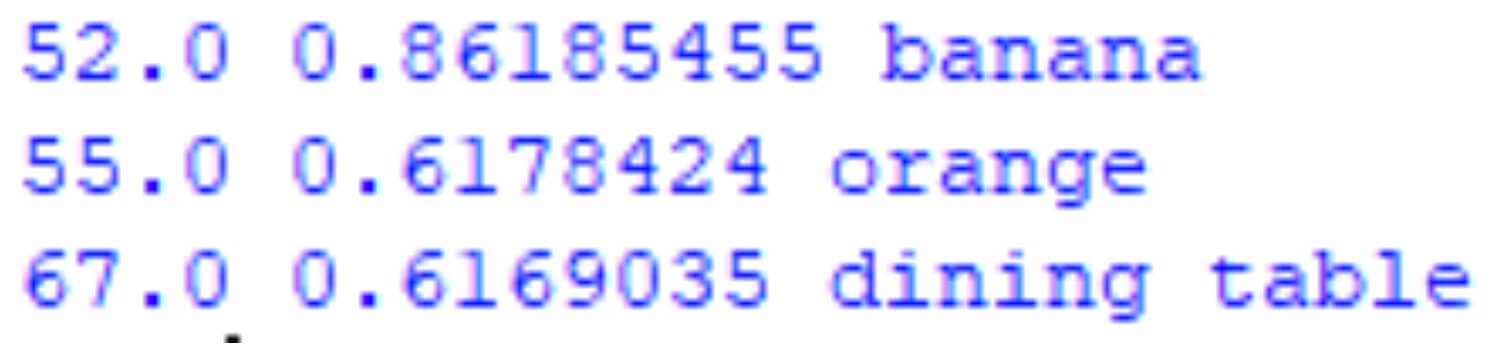
print(str(str(class_id) + " " + str(detection[2]) + " " + class_name))
# Calculate box positions and dimensions
box_x = detection[3] * image_width
box_y = detection[4] * image_height
box_width = detection[5] * image_width
box_height = detection[6] * image_height
# Draw rectangle around the object
cv2.rectangle(image, (int(box_x), int(box_y)), (int(box_width), int(box_height)),
(23, 230, 210), thickness=1)
# Add text label
cv2.putText(image, class_name, (int(box_x), int(box_y + .05 * image_height)),
cv2.FONT_HERSHEY_SIMPLEX, (.005 * image_width), (0, 0, 255))
8. Ausgabe
Das Bild kann mit der Funktion imshow() wie folgt angezeigt werden:
cv2.imshow('image', image)
# Speichern des Bildes (optional)
cv2.imwrite("image_box_text.jpg", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
Hier siehst du die Ausgabe des Bildes mit den erkannten Objekten. Darunter die Klassen-ID in der ersten Spalte, die Wahrscheinlichkeit in der zweiten Spalte und der Klassenname in der dritten Spalte.

Der gesamte Code
Hier findest du den vollständigen Code zur Objekterkennung mit OpenCV und MobileNet:
import cv2
# Vortrainierte Klassen im Modell
ObjectsNames = {
0: 'background', 1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorcycle',
5: 'airplane', 6: 'bus', 7: 'train', 8: 'truck', 9: 'boat',
10: 'traffic light', 11: 'fire hydrant', 13: 'stop sign', 14: 'parking meter',
15: 'bench', 16: 'bird', 17: 'cat', 18: 'dog', 19: 'horse', 20: 'sheep',
21: 'cow', 22: 'elephant', 23: 'bear', 24: 'zebra', 25: 'giraffe',
27: 'backpack', 28: 'umbrella', 31: 'handbag', 32: 'tie', 33: 'suitcase',
34: 'frisbee', 35: 'skis', 36: 'snowboard', 37: 'sports ball', 38: 'kite',
39: 'baseball bat', 40: 'baseball glove', 41: 'skateboard', 42: 'surfboard',
43: 'tennis racket', 44: 'bottle', 46: 'wine glass', 47: 'cup', 48: 'fork',
49: 'knife', 50: 'spoon', 51: 'bowl', 52: 'banana', 53: 'apple', 54: 'sandwich',
55: 'orange', 56: 'broccoli', 57: 'carrot', 58: 'hot dog', 59: 'pizza', 60: 'donut',
61: 'cake', 62: 'chair', 63: 'couch', 64: 'potted plant', 65: 'bed',
67: 'dining table', 70: 'toilet', 72: 'tv', 73: 'laptop', 74: 'mouse',
75: 'remote', 76: 'keyboard', 77: 'cell phone', 78: 'microwave', 79: 'oven',
80: 'toaster', 81: 'sink', 82: 'refrigerator', 84: 'book', 85: 'clock',
86: 'vase', 87: 'scissors', 88: 'teddy bear', 89: 'hair drier', 90: 'toothbrush'
}
# Laden des Modells
model = cv2.dnn.readNetFromTensorflow(
'models/frozen_inference_graph.pb',
'models/ssd_mobilenet_v2_coco_2018_03_29.pbtxt'
)
# Bild laden
image = cv2.imread("dogndapple.jpg")
# Höhe und Breite des Bildes abrufen
image_height, image_width, _ = image.shape
# Blob erstellen
blob = cv2.dnn.blobFromImage(image, size=(299, 299), swapRB=True)
print("First Blob: {}".format(blob.shape))
# Blob als Input für das Modell setzen
model.setInput(cv2.dnn.blobFromImage(image, size=(299, 299), swapRB=True))
# Funktion zum Abgleich der ID mit Klassennamen
def id_Object_class(class_id, classes):
for key_id, class_name in classes.items():
if class_id == key_id:
return class_name
# Modellvorhersage
output = model.forward()
# Ausgabe für alle erkannten Objekte
for detection in output[0, 0, :, :]:
confidence = detection[2] # Wahrscheinlichkeit der erkannten Klasse
if confidence > .35: # Schwellwert
class_id = detection[1]
class_name = id_Object_class(class_id, ObjectsNames) # Klassenname holen
print(str(str(class_id) + " " + str(detection[2]) + " " + class_name))
# Berechnung der Box-Positionen und -Dimensionen
box_x = detection[3] * image_width
box_y = detection[4] * image_height
box_width = detection[5] * image_width
box_height = detection[6] * image_height
# Rechteck um das erkannte Objekt zeichnen
cv2.rectangle(
image,
(int(box_x), int(box_y)),
(int(box_width), int(box_height)),
(23, 230, 210),
thickness=1
)
# Text mit dem Klassennamen hinzufügen
cv2.putText(
image,
class_name,
(int(box_x), int(box_y + .05 * image_height)),
cv2.FONT_HERSHEY_SIMPLEX,
(.005 * image_width),
(0, 0, 255)
)
# Bild anzeigen
cv2.imshow('image', image)
# Optional: Bild speichern
# cv2.imwrite("image_box_text.jpg", image)
# Auf Benutzereingabe warten und Fenster schließen
cv2.waitKey(0)
cv2.destroyAllWindows()
Wenn du jetzt ein eigenes Bild verwenden möchtest, musst du nichts weiter tun, als die betreffende Datei unter dem Ordner models zu speichern und an der Stelle image = cv2.imread("DeinBild.jpg") einzufügen. Beachte aber, dass das Skript nur Objekte innerhalb der vortrainierten Klasse erkennen kann.
Schluss
Dieses Tutorial diente nur als ein kleiner Ausblick in die Objekterkennung. Wir sind im Detail bewusst nicht auf jedes Detail eingegangen, da es den Rahmen in diesem Eintrag sprengen würde. Wir hoffen, es hat dir dennoch gefallen.
Ihr dürft euch zukünftig auf noch mehr Einträge über Bilderkennung, Machine Learning und Neuronale Netze freuen.
Teil uns doch in den Kommentaren mit, was du dir als nächstes wünschst. Wir freuen uns!
Related posts
-
 Raspberry Pi Kamera installieren
Diese Anleitung erklärt dir den Aufbau deiner Raspberry Pi Kamera und wie du sie anschließen, einrichten, testen und...Mehr lesen
Raspberry Pi Kamera installieren
Diese Anleitung erklärt dir den Aufbau deiner Raspberry Pi Kamera und wie du sie anschließen, einrichten, testen und...Mehr lesen -
Raspberry Pi Kamera im LXTerminal ansteuern
In diesem Tutorial findest du in einem kompakten Überblick alle erdenklichen Befehle, um deine Raspberry Pi Kamera...Mehr lesen
-
Nistkasten Kamera Bauanleitung – Kamera für Vogelhaus mit Raspberry Pi selber bauen
In diesem Tutorial zeigen wir dir, wie du mit einem Raspberry Pi und einer Electreeks Raspberry Pi Kamera eine eigene...Mehr lesen
-
Internet Live-Stream mit einer Raspberry Pi Kamera auf YouTube mit Motion-Eye-OS
Erstell jetzt mit deiner Raspberry Pi Kamera einen Livestream auf YouTube mit MotionEyeOS und teil ihn mit anderen...Mehr lesen
-
Fernzugriff auf MotionEye-OS und Raspberry Pi durch Portfreigabe und DynDNS
Aus dem Internet auf Motion Eye zugreifen. Ports freigeben im Router und per DynDNS dauerhaft aus dem Internet...Mehr lesen
Leave a comment